19 Jan

Lightning talk blog
Education is an important part of our lives. We know that and this is the reason why we have regular tech-talks in Instea. Last week we decided to present some short technical IT innovations to each other. We would like to share it with you. Here you are. 🙂
Actors
The actor model is a programming paradigm, similar to functional programming or object-oriented programming. If applied correctly, it can be effective in writing highly scalable, highly concurrent and fault tolerant applications.
The fundamental unit of computation in the actor model is an actor.
If you want to start playing with actors, you need some implementation of the actor system. Erlang comes with native support for actors. In other languages, there are libraries like Akka, Akka.NET and more in other languages.
How actors work
These are the rules of the actor model:
All computation is performed within an actor
All the code is organized into actors
Actors can communicate only through messages
Every actor, when created, is given an address (which is unique)
Actors can communicate with other actors via messages, but can not directly access their state
Messages are pieces of immutable data
Messages are sent to the destination mailbox with at-most-once guarantee and with no guarantees of order
Destination actor receives the messages one-by-one (this creates a single-threaded illusion)
In response to a message, an actor can:
Change its state or behavior
Send messages to other actors
Create a finite number of child actors
Hierarchy and fault tolerance
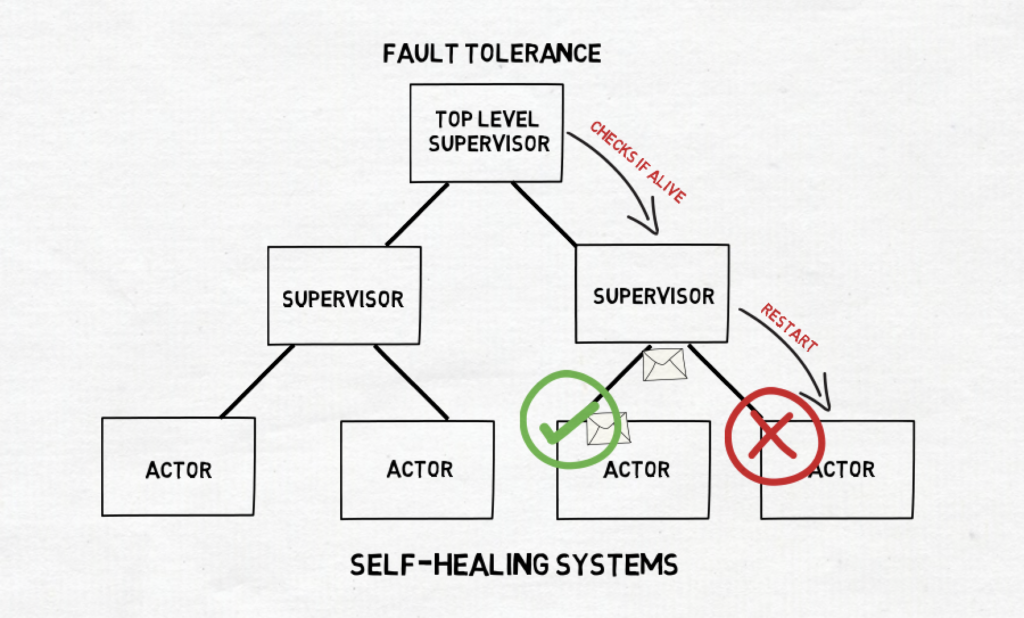
In the actor system, actors are organized into a hierarchy. Each actor has exactly one parent actor and its address is usually a path in the hierarchy. The root actors are usually provided by the library and have a special status.
Parent actor has a responsibility to supervise its children actors. That means that when any kind of unexpected failure happens in the child, it gets notified and has to choose a strategy:
– Resume the actor, keeping its accumulated internal state
– Restart the actor, clearing out its accumulated internal state, with a potential delay starting again
– Stop the actor permanently
– xCustom strategy
The supervisor can also decide to bubble the failure up.
Overall this technique allows to isolate and contain the failure without it impacting the whole system.
Example code
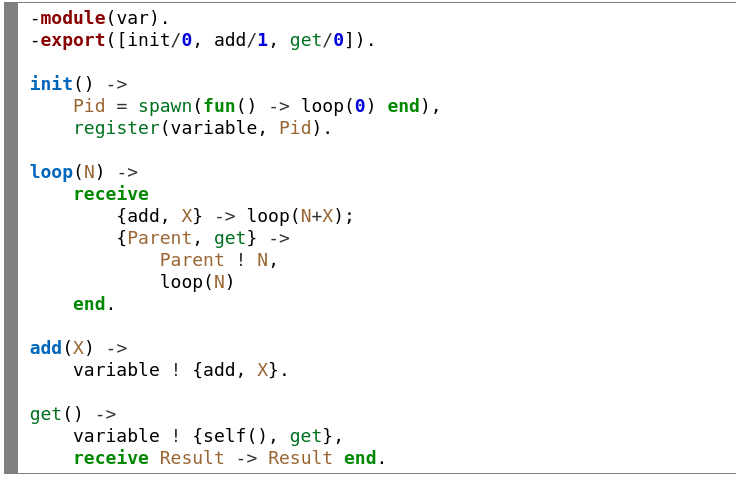
This is a simple code in Erlang defining one actor (loop function). For simplicity it’s just a solitary actor instead of a full blown actor system.
Here the process is equivalent to an actor. It’s basically a function that is initiated with some initial state (loop(0)) that receives messages (receive block waits for a message and based on pattern matching chooses the code to be executed – like switch in C-like languages).
The call of itself (loop(N+X), loop(N)) is just a way of recursively setting a new state and continuing the operation.
Also of note is register(variable, Pid), which assigns an address to the actor. And Parent ! N means sending a message with content N to the address that was provided in the message.
Python – for Node.js developers
As Javascript and Java being two programming languages mostly used across Instea’s projects, the company is accommodating other languages as well. This time I talked about the python that was used recently to develop a restful microservice for one of our customers. I have presented an opinionated modern python tech stack based on the FastAPI framework and other recommendations. The basic concepts, development experience and tools turned out to be similar to the javascript/node.js. Therefore I have made some analogies and comparisons between those two worlds. Find below some of the key points:
– Python includes optional built-in types that can be checked with tools like mypy (no need to transpile code)
– Modern ASGI servers like Uvicorn use an asynchronous concurrency model running on a single thread and using an event loop which is basically the same architecture as the node.js
– FastAPI is a modern framework to build an API in python including many features like routing, openapi documentation, DI, security features, …
– Dependencies are managed in pypi repositories using tools like pipenv (similar to npm/yarn)
– Jetbrains IDE for python – pycharm
– Other tools: pytest for testing, flake8 for code linting and black for code formatting
Web Workers easily (with create-react-app)
Running JS code in a browser was single-threaded for a very long time. I needed to make extensive computation but the responsiveness of the browser tab has suffered. Nowadays it is possible to off-load such work with Web Workers. You write an extra file, load it with a special API and communicate back and forth with messages.
It sounds simple enough but how can I create an additional entry point for my worker file? Here comes the workerize-loader. It works out of the box with create-react-app (or webpack if you want). And it is easy to use.

No special message exchange (which might be useful in special situations) – simply call an asynchronous function.
It works okay also with Typescript – you just need to add one declaration file and you can use your workers with all the types. See Github issue for more details.
Google maps – HTML marker
Sometimes we need to add markers on Google maps, that are more complicated than simple image (for example, we want to convey more information than simple gps position). In this situation we quickly realize that Google Maps markers are hard to work with.
First obvious solution was to use multiple markers, which did not improve our situation much. They are hard to align, almost impossible to debug and when we need to use a clusterer we have to add some custom logic that counts how many markers there are.
Best solution is to use HTML to define markers, which is easily possible, but may not be so obvious just from documentation.
Basically, what we need to do is:
– create new class that inherits from class google.maps.OverlayView
– implement following functions:
– onAdd (create DOM element and set content)
– draw (set DOM element position)
– onRemove (cleanup function)
– getDraggable + getPosition (not documented)
Last two functions are not documented, but we get errors if those are not defined.
And there is example of our HTMLMarkerer class:

Recoil
As React developers, we are facing issues with the shared state of our components. Luckily for us, some libraries come to our aid. One of the best known is Redux. So we set a redux store, reducers, define some actions, make action creators, map state and dispatch to our components. For a developer unfamiliar with the library, these concepts take some time to learn. But in most applications, we are not done yet. We also need to support some asynchronous behavior, so we throw Redux-Saga or Redux-Thunk into the mix, along with the concept of middlewares that we must learn, and of course, nuts and bolts of the used middlewares.
Isn’t there some more straightforward way to deal with the shared state? Luckily for us, there is a library that comes to the rescue – Recoil. Recoil has the advantage that it is developed by Facebook and solely for React. The API looks more ‘reactish’, familiar, and there aren’t so many concepts. The key players are shown in the next diagram.
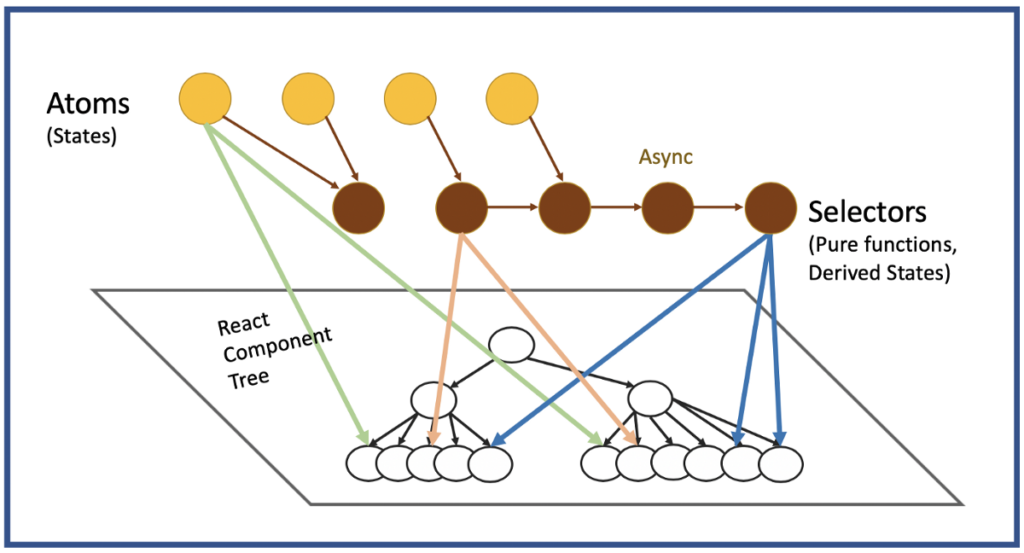
The diagram is a Recoil data-flow graph. In the plane at the bottom of the chart, we have something already known to us – React component tree. But nodes outside of the plane can be new to us.
The first type of nodes marked yellow are called atoms. In Recoil, we don’t have one centralized store as in Redux, but we have units of the state called atoms. The atoms hold the state. We can read from them and write to them. They provide the state either directly to the React components or indirectly via selectors.
Selectors are the nodes marked as brown in the data-flow graph. They work with data gathered from one or more atoms, making derived data and passing it to the React components. The catch when using selectors is that we must ensure that we define them as pure functions. It’s important to remember because Recoil caches the outputs for arguments that were at least once passed to the function. If the function’s output is not always the same for the same arguments, the function is not pure and thus can’t be used as a selector. Selectors can also be asynchronous, making them a perfect place for making requests. But keep in mind that the function should be pure. You should make requests in selectors (without using techniques that bypass this limitation) only for data that you suppose will not change in the application’s lifetime. Mutating requests are not possible. However, using request id in selectors, we can bypass this limitation.
By now, we should be familiar with the concepts of Recoil and can compare the complexity with Redux. My personal opinion is that in this battle, Recoil absolutely wins. As said at the beginning of this article, Recoil was made solely for React, and unsurprisingly is well-designed for use in React. Authors also promise the cherry on top, support for the concurrent rendering (which can’t be efficiently and without bugs supported by Redux now), a new performance feature for React 18.
So are there any reasons we should stick with the Redux for new projects? Adopting Recoil has (at least) two significant issues. The first one is that at the time of writing, it is an experimental library. The developers at Facebook are updating it with new features and solving bugs, but it may not be in the ideal state for use in enterprise applications. The second issue, reasonably linked with the first, is that there are not many developers at the enterprise level that know Recoil, and additional time would have to be spent on learning the library, along with the struggle of a smaller community.
SonarCloud
After receiving an email newsletter about SonarCloud, I decided to look into it – service for continuous code quality and security review sounded like a good idea. As we (Instea) have some projects only a few developers are working on, there can sometimes be a problem to get code reviews done in reasonable time – this problem further multiplies with flexible working time, home office, part-time employees, and so on.
SonarCloud (as name implies) runs in the cloud, so initial setup is really easy and fast – just a few clicks and you are up and running, there is no need to download and host anything by yourself. After the first analysis you are presented with an overview page, where you can see the overall status of your project with issues (of different severity) – even with explanations and estimated time to fix – and different measures so you can assess how bad (or good) your project is.
In case you do not have time to tackle all your existing technical debt (probably no one has), the next best thing you can do is to make sure you will not create new issues. With new code analysis and quality gates you can set up automatic control of development branches and pull requests – you are even able to prevent PR that lacks necessary quality or test coverage from merging.
SonarCloud covers 24 programming languages and comes with the extension SonarLint for some IDEs, so you can fix issues before they exist. We are currently trying SonarCloud to find out whether it is a good fit for our company and to assess code quality of one JAVA project (~70k LOC). Stay tuned for a separate blog post about our trial period – we are eager to share our opinion and insights with you!
Eager for more?
We have also talked about other interesting topics like Low Code and No Code Platforms, How page loading times influences UX and conversions or How to make better BE with Nest.js. If you are interested in hearing more about it, let us know in the comments or write us an email.






